


[THREAT ANALYSYS] 감염될 때마다 변신하는 바이러스를 막아라
<다형성 바이러스 Win32/Xpaj.C 분석>
악성코드 제작자와 분석가의 치열한 두뇌 싸움은 현재진행형이다. 악성코드 제작자들은 분석가들의 추적을 따돌리기 위해 각종 최신 수법들을 이용하고 있다. 그 중 하나가 다형성(Polymorphic) 기법이다. 이를 이용하여 바이러스를 제작하면 파일이 감염될 때마다 그 형태가 변하여 감염여부를 확인하기 힘들다. 다형성 기법을 이용한 바이러스가 바로 다형성 바이러스이며, 이러한 복잡한 형태의 바이러스는 점점 증가하고 있는 추세이다. 이 글에서는 다형성 바이러스의 일종인 Win32/Xpaj.를 자세히 분석해보고자 한다. 이를 통해 다형성 바이러스의 특징과 수법을 이해할 수 있기를 기대한다.
다형성 바이러스 Win32/Xpaj.C 분석
Win32/Xpaj 바이러스는 2008년에 처음 발견되었으며 2009년에는 변형인 Win32/Xpaj.B형이 발견되었다. 그리고 최근에는 진단 및 치료가 더욱 어렵게 되어 있는 또 다른 변형인 Win32/Xpaj.C형이 발견되었다.
대부분의 바이러스 제작자들은 원본 정상파일이 손상되는 위험을 피하기 위해 복잡하게 원본 파일을 변경하지 않는 것이 일반적이다. 그러나 최근에 발견된 Win32/Xpaj B형, C형 바이러스 같은 경우는 예외라고 할 수 있다. Win32/Xpaj B형, C형 바이러스들은 EPO(Entry-point Obscuring)와 다형성 바이러스 특징을 모두 가지고 있어서 바이러스의 시작지점과 공통적인 바이러스 몸통 부분을 찾기가 어렵다.
좀 더 자세히 살펴보면 정상 CALL, JMP 명령어를 임의로 패치 하여 자신이 원하는 코드 상의 위치로 분기하도록 하였으며 바이러스 몸통 부분으로 진입하기 위해 정상 서브루틴들을 임의로 변경하였다. 또한 명확한 바이러스 감염 표시가 없어서 파일의 감염 여부를 확인 하는 것도 다른 바이러스에 감염된 파일에 비해 쉽지 않다.

[표 1] 변종별 감염 특징 및 특이사항
* EPO(Entry-point Obscuring) virus
Entry-point Obscuring을 우리말로 하면 ‘시작 실행시점 불명확화'라고 할 수 있을 것이다. 즉, 일반적인 바이러스처럼 정상파일의 EP(Entry-Point:프로그램의 진입점)를 변경시켜 바이러스 자신이 실행시키고자 하는 것을 실행시키는 것이 아니라 임의의 CALL 명령어 또는 JMP 명령어 부분을 바이러스 진입지점으로 수정하는 바이러스들을 공통적으로 EPO라고 칭한다. 이런 EPO기법을 안티바이러스 엔진에서 진단하기 어려운 이유는 정상파일 코드영역 중 어느 부분의 CALL 또는 JMP 명령어가 변경되었는지 알 수 없기 때문에 변경되는 패턴을 찾지 못하면 코드영역 진입점부터 끝까지 스캔해서 찾아야 하는 어려움이 있기 때문이다.
* 다형성(Polymorphic) 바이러스
파일이 감염될 때마다 그 형태가 변하는 다형성(Polymorphic)기법을 이용하여 감염여부를 확인하기 어렵도록 한 바이러스를 다형성 바이러스라고 한다. 일반 백신에서 바이러스 코드의 특징을 찾아 감염 여부를 확인 한다는 것이 알려지면서 바이러스 제작자들은 암호화 방법을 구현하는 코드들을 변화시켜 특징을 찾기 어렵도록 했다. 암호화를 푸는 부분이 항상 일정한 단순 암호화 바이러스와는 달리 암호화를 푸는 부분조차도 감염될 때마다 달라지도록 만든 것이다.
[표 1]은 변종별 특이사항을 표로 나타낸 것이다. [표 1]에서 보이는 것처럼 최초 발견된 A형 같은 경우에는 감염 위치가 마지막 섹션으로 고정이고 CALL 명령어들만 패치 되어 있는 경우라서 진단/치료가 비교적 쉬웠다. 그러나 최근에 발견된 C형은 감염 섹션이 임의적이고 진단 후 치료에 필요한 데이터들이 암호화되어 있어 치료도 쉽지 않다.
1. 감염된 파일 특징
Win32/Xpaj.C형에 의해 감염된 파일은 [그림 1]과 같은 특징을 가진다. 파일에 따라 패치된 CALL이 있을 수도 있고 없을 수도 있지만, 정상 서브루틴들이 임의로 감염되는 것은 동일하게 나타난다. 원본 데이터들은 바이러스 몸통 부분에 인코딩 되어 저장되어 있다. 패치된 CALL은 감염된 서브루틴으로 분기되도록 동작을 하고 감염된 서브루틴들은 바이러스 몸통 부분의 데이터들을 이용해서 실제 바이러스 코드가 실행되도록 동작 한다.
바이러스 몸통은 크게 4부분으로 분류할 수 있다. 첫 번째는 바이러스 감염 동작을 하는 ‘Virus Code’ 부분, 두 번째는 정상 서브루틴이 인코딩 되어 있는 ‘Encoded Original Subroutine’ 부분, 세 번째는 디코딩과 다양한 용도의 데이터를 추출할 때 사용되는 ‘4bytes Data’ 부분, 그리고 마지막으로 'Virus Code' 부분을 디코딩하고 그 후 분기하기 위한 코드들이 들어있는 'Decoding Routine Space' 부분이다.
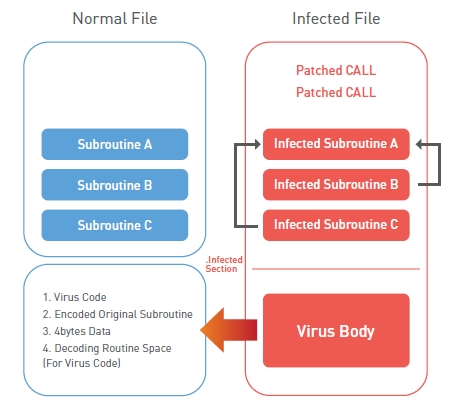
[그림 1] 감염된 파일의 특징
[그림 2]는 감염된 서브루틴을 보여주고 있는데 여기서 Win32/Xpaj.C형의 특징 중 하나를 확인할 수 있다. 기본적으로 코드 상의 PUSH EBP, MOV EBP, ESP 명령어의 데이터값은 '55 8B EC' 인 경우가 대부분이다. 그러나 감염된 파일은 같은 명령어의 데이터값이 '55 89 E5'인 것을 확인할 수가 있다. 이것을 바탕으로 OllyDBG(Olly Debugger)와 같은 디버거 툴에서 감염된 서브루틴을 찾을 때 바이너리 검색을 통해 '55 89 EC'가 어디 있는지 확인한다면 쉽게 찾을 수 있다.
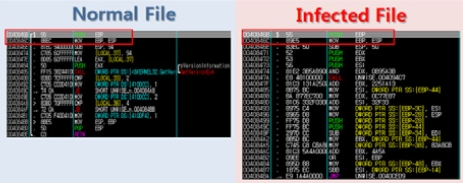
[그림 2] 감염된 서브루틴
Win32/Xpaj.C형의 가장 큰 특징 중 하나는 바이러스 몸체를 삽입하는 섹션을 선택하는 기준을 정확하게 판단하기 어렵다는 것이다. [그림 3]처럼 같은 섹션 개수와 이름을 가지고 있더라도 파일속성과 Virtual Size 등의 조건에 따라 바이러스 몸체가 삽입되는 대상 섹션이 달라진다. [그림 3]과 같은 경우 '.edata'섹션에 바이러스 몸체가 삽입된 경우와 '.rsrc' 섹션에 삽입된 경우이다. 두 파일의 차이는 아래 파일(ir41_qc.dll)의 '.edata' 섹션에는 'IMAGE_SCN_MEM_SHARED' 속성이 있는데 Win32/Xpaj.C형은 해당 속성이 있으면 삽입할 수 없는 섹션으로 판단하고 아래에 있는 섹션에 바이러스 몸체를 삽입한다는 점이다.
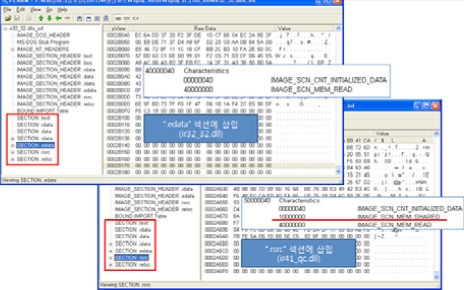
[그림 3] 섹션 속성에 따라 다른 감염 대상 섹션
[그림 4]는 위에서 설명한 것처럼 바이러스 몸체를 삽입하고자 하는 섹션을 찾는 과정을 다이어그램으로 나타낸 것이다. 바이러스가 감염 대상을 찾을 때 섹션 정보를 아래에서부터 확인한다. 그리고 '.reloc' 섹션은 감염 대상이 되지 않는 섹션으로 판단하고 '.rsrc' 섹션은 일차적으로는 감염 대상이 되지 않는 섹션으로 판단하지만 바로 위의 섹션 또한 감염 조건에 맞지 않으면 다시 '.rsrc' 섹션의 속성을 확인해서 감염조건이 맞으면 해당 섹션에 바이러스 몸체를 삽입한다. 그리고 삽입 가능한 섹션들의 공통적인 특징으로는 해당 섹션의 속성에 'IMAGE_SCN_MEM_SHARED' 속성이 없어야 하고 Virtual Size가 너무 크지 않아야 한다.
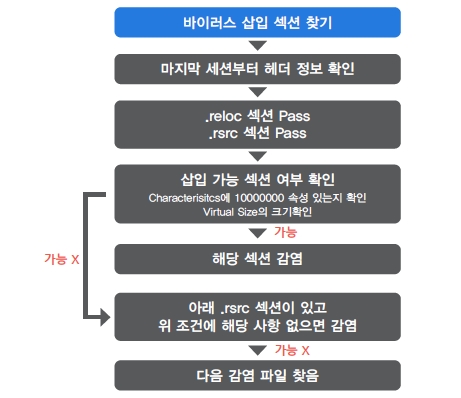
[그림 4] 바이러스 몸체 삽입 대상 섹션을 찾는 과정
2. 감염된 파일의 동작
감염된 파일이 실행되면 처음에는 정상 루틴을 돌다가 패치 된 CALL/JMP를 만나면 바이러스가 원하는 메인 서브루틴 또는 다른 서브루틴으로 분기하고 다른 서브루틴들은 다시 메인 서브 루틴으로 분기하는 동작을 한다.
이렇게 분기된 메인 서브루틴에서는 앞선 [그림 1]에 표기된 다음의 과정을 수행한다.
1. 바이러스 몸체의 '3. 4 bytes Data'들을 이용해서 필요한 데이터들을 얻어온다.
2. '4. Decoding Routine Space' 부분에 있는 데이터들을 이용해서 '1. Virus Code' 부분을 디코딩하고 분기를 한다.
3. 분기된 바이러스 코드에서는 인코딩 되어 있는 '2. Encoded Original Subroutine’ 부분을 디코딩해서 정상 루틴을 실행하고 시스템의 ‘.dll’, ‘.exe’ 등의 파일들을 검색해 감염 조건 등을 확인해서 정상파일들을 감염하는 동작을 한다.
[그림 5]는 간단한 정상파일들의 분기과정들에 비해 감염된 파일의 경우는 복잡한 분기과정을 거치는 것을 보여주고 있다.
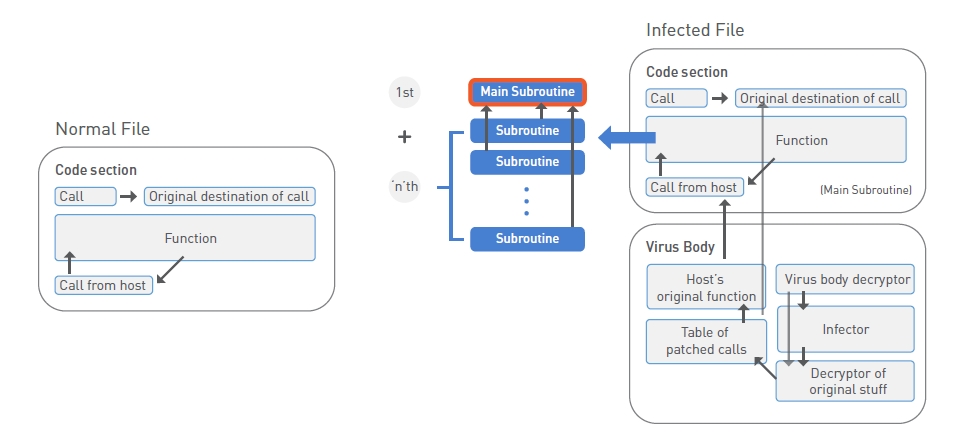
[그림 5] 정상파일과 감염된 파일의 동작 차이
2.1. Main Subroutine
메인 서브루틴은 상당히 복잡한 과정을 거친다. 바이러스 코드 부분을 정확하게 동작하고 감염시키기 위해서 다양한 데이터들을 추출하는 과정을 거치는데 그 중 가장 먼저 추출하는 데이터는 주소값 연산할 때 'Base Address'로 사용하기 위한 '기준 주소'를 얻는 것이다. [그림 6]은 예제 파일의 코드 상에서 기준 주소가 되는 부분을 보여주고 있다. 대부분 이 '기준 주소'는 메인 서브루틴에서 처음으로 호출되는 CALL 명령어의 Return 주소가 된다.
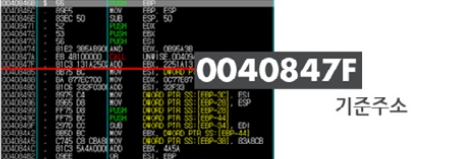
[그림 6] 메인 서브루틴에서 '기준 주소 위치'
[그림 7]은 위에서 구한 '기준 주소'와 바이러스 몸통에 저장된 '3. 4 bytes Data'([그림 1])들을 이용하여 연산하는 과정을 보여주고 있다. 4개의 4 bytes Data들([그림 1]), 세 번의 덧셈연산과 세 번의 XOR 연산, 그리고 코드 상의 3개의 상숫값들이 짝을 이루고 있다. 이 연산을 통해서 디코딩 루틴의 시작 주소, 디코딩 대상 코드의 시작 주소 등의 데이터를 추출해 낸다.

[그림 7] ‘3. 4bytes Data’를 이용한 연산과정
위의 과정을 거치면서 추출한 데이터들로 필요한 루틴을 실행하게 되는 'ZwProtectVirtualMemory' API를 이용해서 바이러스 몸체가 있는 부분의 메모리 속성을 변경해서 데이터를 ‘Write’ 할 수 있게 한다. 그리고 '3. 4 bytes Data' [그림 8]영역에서 데이터들을 4 bytes씩 읽어와 PUSH/POP의 동작으로 특정 영역에 데이터를 덮어쓰면서 디코딩 루틴을 생성하고 한번 더 덮어써서 디코딩된 바이러스 코드로 JMP 명령어를 통해 분기될 수 있도록 한다.
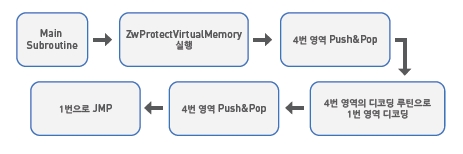
[그림 8] 바이러스 몸체 부분을 디코딩하기 위한 메인 서브루틴의 주요동작
2.2. Virus body decryptor
메인 서브루틴에 의해 생성된 디코딩 루틴은 [그림 9]와 같은 코드로 모든 Win32/Xpaj.C형 바이러스에 동일하게 나타난다. 첫 4bytes는 스택에 저장해둔 4bytes 값으로 바꾸고 그 후에는 역시 스택에 저장해둔 데이터들을 이용해 덧셈연산으로 첫 4bytes 이후의 데이터들을 디코딩한다. 스택에는 디코딩하고자 하는 크기 또한 저장되어 있어 4 bytes 씩 디코딩할 때마다 그 크기를 줄여주면서 원하는 만큼의 디코딩 수행이 가능하다. 이를 좀 더 쉽게 설명하기 위해 그림과 동작과정을 표현한 것이 [그림 10]이다.
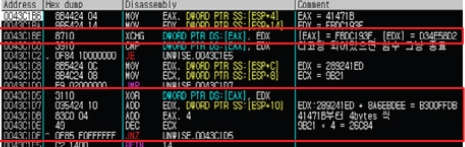
[그림 9] Virus Code 디코딩 루틴
앞에서 설명한 것처럼 첫 4 bytes는 스택에 저장된 데이터를 그대로 덮어쓰고 그 뒤의 데이터들은 4 bytes 씩 스택에 저장된 다른 데이터들을 이용해서 디코딩한다. 즉, [그림 10]내의 스택에 보면 각 데이터값들을 '디코딩 연산 값. 1,2,3'으로 표현을 하였다. 여기서 '디코딩 연산 값. 2'를 하나씩 더하고 '디코딩 연산 값3'과 더한 후 4 bytes 이후의 값들과 xor 연산을 하면서 디코딩한다.
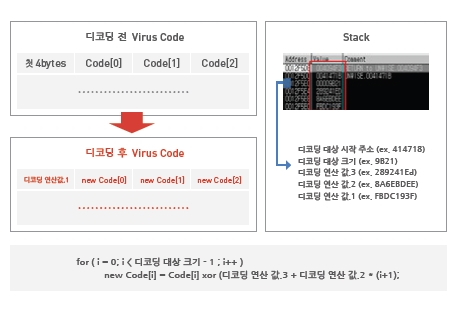
[그림 10] 디코딩 전후의 변화와 디코딩 과정의 수식표현
이런 과정들을 거치면서 바이러스 코드부분을 디코딩한 후에 그곳을 분기하면서 본격적으로 감염동작을 하기 위한 작업을 한다.
2.3. Infector
디코딩된 바이러스 코드부분을 간단하게 요약해서 감염동작 하는 부분만을 뽑아낸다면 [그림 11]과 같다고 할 수 있다. 실제로는 많은 양의 코드들이 있고 하나의 API 주소를 얻어오기 위해서도 많은 과정을 거친다. 그 중에는 굳이 필요 없는 'garbage code'가 많았는데 이 때문에 분석이 쉽지 않았으며 많은 시간이 필요했다.
이 복잡한 Win32/Xpaj.C형은 다음의 동작을 수행한다.
1. 시스템에 있는 '.exe', '.dll' 등의 파일들을 'MapViewOfFile' API를 이용해 메모리에 매핑한다.
2. 파일 헤더 부분과 섹션 정보들을 읽어서 '감염 대상파일인지', 그렇다면 '바이러스 몸체는 어느 섹션에 삽입해 놓을 것인지'를 결정하는 동작을 한다.
3. 감염 조건에 맞는 파일과 섹션을 찾는다면 '%temp%' 폴더에 임시 파일을 생성하여 다시 'MapViewOfFile' API를 통해 메모리에 매핑하고 정상파일에 바이러스에 감염된 상태의 데이터들을 저장하고 '.tmp'파일을 생성한다.
4. 정상파일을 삭제하고 같은 경로와 이름으로 '.tmp'파일을 복사하고 삭제하는 방식으로 감염대상 파일들을 감염한다.
5. 2번의 동작에서 감염 대상 파일과 조건에 맞는 섹션을 찾지 못한다면 바로 'UnMapViewOfFile'과 'CloseHandle' API를 호출해 매핑되어 있는 메모리 영역과 파일 핸들을 끊고 다음 파일을 다시 매핑해서 파일을 스캔 하는 동작을 한다.
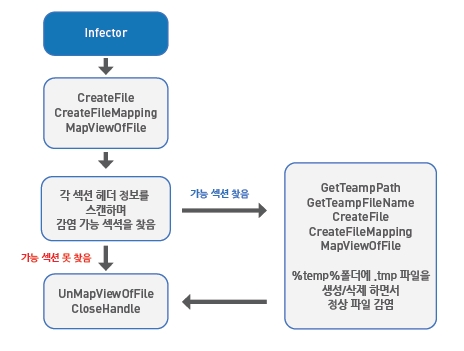
[그림 11] Win32/Xpaj.C의 파일 감염 동작
3. 진단 & 치료
정상파일이 바이러스에 감염된 후 확연히 구분되는 특징이 있다면 이 부분을 진단에 이용하면 된다. 그러나 Win32/Xpaj.C형은 정상파일이나 감염된 파일이나 파일의 차이가 거의 없어서 현재 대부분의 AV 업체들이 진단에 어려움을 겪고 있다. 또한 진단하더라도 파일마다 많은 시간을 들여 스캔해야 하므로 엔진의 진단속도 이슈 역시 발생할 수 있다. 이러한 이유로 진단하는 데 어려움이 있지만 V3에서는 분석을 통해 확인된 정보와 바이러스 디코딩 루틴을 에뮬레이팅하는 등의 방법으로 Win32/Xpaj.C형을 진단한다.
바이러스는 진단보다 치료에 더 많은 시간과 리소스를 필요로 한다. 일반적으로 바이러스를 치료하기 위해서는 치료 데이터가 필요하다. 이 치료 데이터들을 통해 원본 데이터와 위치정보를 가지고 복원과 바이러스 몸체 부분은 삭제하는 식으로 치료를 한다. 그러나 Win32/Xpaj.C형은 그 치료 데이터를 찾기가 쉽지 않았고 분석결과 다른 일반적인 바이러스들과 다르게 이 치료 데이터들조차 인코딩되어 따로 저장되어 있었다. 즉, 해당 치료 데이터를 얻기 위해서는 1차적으로 디코딩 작업을 진행한 후에 정보를 추출할 수 있었다.
패치된 CALL이나 서브루틴의 앞부분 '32bytes(0x20) 데이터'에 치료를 위한 정보가 있는 것을 확인하였고 그 부분에 치료할 위치의 RVA, 치료할 크기, 다음 패치된 CALL의 위치 등을 유추할 수 있는 정보가 있었다. [그림 12]는 패치된 CALL에 대한 치료 정보 데이터와 '5bytes JMP 명령어들'과 각 데이터들에 의해 어떤 정보들을 알 수 있는지 보여준다. 구조는 '32bytes(0x20) 크기의 정보데이터'와 '5bytes의 JMP명령어'가 짝으로 패치된 CALL의 수 만큼 정보를 가지고 있다. 그리고 '5bytes의 JMP명령어'는 패치 전 정상 CALL명령어에 의해 분기하는 곳의 RVA 값이다.

[그림 12] 패치된 CALL명령어 치료 데이터
정상 서브루틴 또한 위와 같은 방법으로 데이터가 저장되어 있다. 차이라면 '32bytes(0x20)' 이후의 코드 부분에 '1byte 디코딩'을 한 번 더 해주어야 정상 코드가 나온다는 것이다. [그림 13]은 서브루틴을 치료하기 위해 필요한 '32bytes(0x20)'의 치료 데이터를 보여주고 있다. 이 치료 데이터들의 xor연산을 통해 치료할 위치와 크기 그리고 다음 서브루틴 치료를 위한 offset상의 위치 등을 알 수 있다.

[그림 13] 서브루틴 치료 데이터
그리고 '1byte 디코딩'을 통해 정상 서브루틴의 코드를 완성한다. [그림 14]의 상단에 디코딩 코드가 있는데 디코딩 하려는 데이터와 '32bytes(0x20)'의 첫번째 값 '4a'를 xor연산하는 것을 나타내고 있다. 처음으로 완성된 정상 서브루틴의 초반에는 '0x90909090…'의 데이터를 갖는데, 이는 메인 서브루틴을 나타내는 시그니처로 볼 수 있다. 마지막 5bytes는 덮어 쓴 원본코드 다음 명령어로 분기하는 JMP명령어가 포함되어 있다.
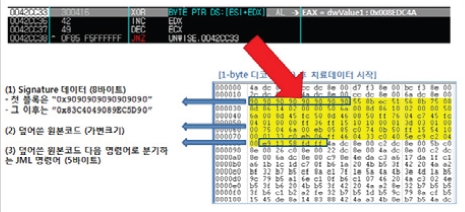
[그림 14] 1byte 디코딩
원래 정상 루틴에서는 주소값들이 정상 코드 영역으로 분기되도록 그 값을 가지고 있는 것이 일반적이다. 그러나 바이러스에 감염되고 디코딩된 후의 정상루틴은 바이러스 영역 내의 주소에서 동작하므로 그 주소값들을 바이러스 영역 내의 디코딩 된 정상 루틴 부분으로 보정해주는 작업을 추가로 해야 한다. 이는 바이러스 코드에서도 그대로 보정 후에 실제 디코딩된 정상 루틴을 실행시킨다.
4. 결론
일반적으로 바이러스는 최대한 시스템 내의 많은 파일을 감염시키고 분석가들이 진단/치료하기 어렵게 한다. 그러나 Win32/Xpaj.C형은 경우는 까다로운 감염 조건 때문에 다른 바이러스들에 비해 많은 파일이 감염되는 편은 아니다. 대신 감염이 까다로운 만큼 진단/치료에 많은 시간과 노력이 필요하게 되어 있다. 하루, 이틀이 아니라 1주, 2주, 아니면 한 달에 걸쳐서 바이러스와 싸워야만 진단/치료법을 적용할 수 있을 것이다. 이에 '바이러스 치료에 새로운 접근법이 필요하지 않을까?'하는 생각들이 스쳐 지나가곤 했다. 정상파일들을 백업 해놓고 이들이 바이러스에 감염된 것으로 확인되면 백업 해놓은 정상파일로 교체해주는 치료는 어떨까? 물론 시스템에 부하가 발생하고 저장 공간도 부족할 것이다. 그렇지만 최근의 클라우드 기술과 파일을 MD5 또는 SHA1값으로 관리하는 방법 등을 접목한다면 안티바이러스 업체들에 조금이라도 희망적인 방법이 나타나지 않을까 생각해본다.
바이러스와 치료에 대한 특성을 잘 알고 있는 악성코드 제작자들은 점점 늘어가고 더불어 다형성 바이러스와 같이 분석뿐만 아니라 진단/치료가 어려운 악성코드들이 계속해서 발전할 것이다. 이에 AV업체들도 정보와 기술을 자신만의 재산이라 생각하지 말고 지식을 공유하고 함께 고민해본다면 더 나은 방법과 정보가 생겨날 것이라 기대한다.@
- 안철수연구소



